How to transform your data using Data Pipelines
Learn how to change the structure of your connected data using our no code SQL themed tools
The simplest use case of Data Pipelines besides data inspection is data migration.
Data migration is simply copying or moving data from a data source to a target data destination. For example, you could set up a schedule to copy an AWS DynamoDB table to a Google Sheet on an hourly basis to make the data accessible for users without access to DynamoDB. This is a simple use case where the focus is on the moving of the data.
Data Pipelines supports much more complex use cases where the data is not only moved but also transformed.
In the pipeline builder view, you will find most common SQL operations such as SELECT, GROUP BY or JOIN, etc.
Once some data is loaded in the pipeline, these operations can be applied to it. A preview will be displayed which shows you how the final output is going to look when written out. There is no limit on the number of operations that can be applied to a pipeline. Each operation is displayed on the right in the Steps column. Steps are executed sequentially and can be removed or edited.
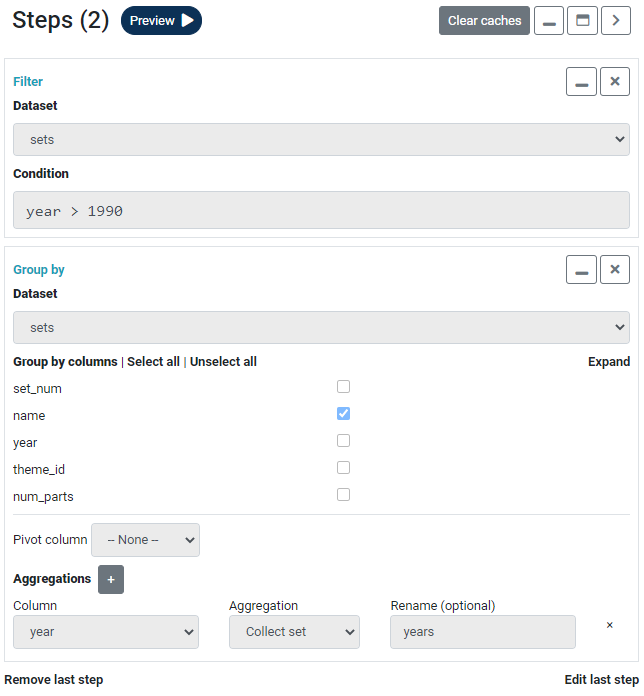
Operations are grouped into two with one group titled "Transform a dataset", the other "Create a new dataset". The difference is that the former will apply an operation inline (update the dataset the operation is being applied to) whereas the latter will create a new dataset from the result. For example, there is a Join operation in each group. One will update the left side of the join with the resulting dataset, the other will create a new dataset from it.
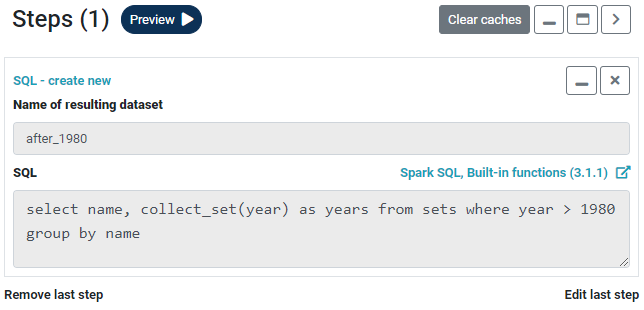
For those familiar with Apache Spark, it is possible to enter native Spark SQL. All Spark functions are supported. The equivalent of the above two operations via Spark SQL would be as follows
Operations applied in Preview mode will be applied when the pipeline runs either via Quick Write or the Scheduler.