How to Map and Create New Columns
Mapping and adding columns using our built-in widget is a powerful feature you can use to build your data pipelines
In Data Pipelines it is possible to map (update) and add new columns to a dataset containing either a literal value or a value derived from other columns. This is done by using the 'Add / Map column' widget in the pipeline builder (Figure 1.).
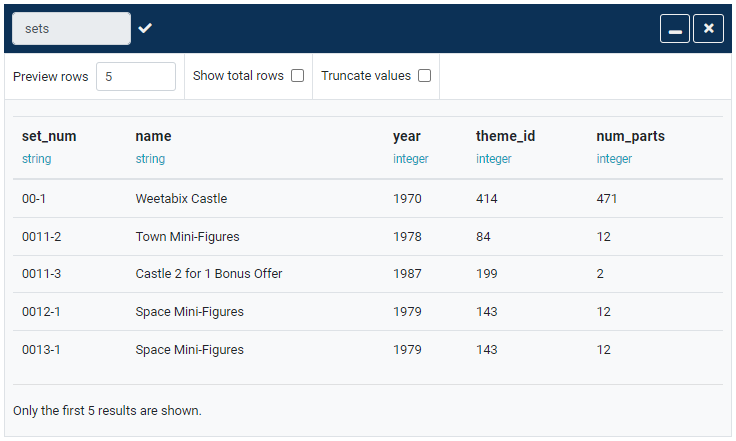
We will be using the dataset in Figure 2. for this demo:
Multiple columns can simultaneously be mapped and added using the widget. In Figure 3. the widget is configured to update the year column by multiplying its values by 2 and add a new column containing the literal 'DP Demo'.
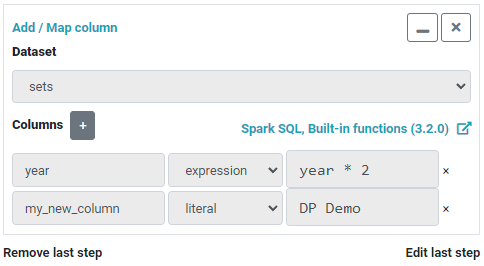
Notice that the year column already exists in the dataset whereas the my_new_column does not. After updating the pipeline preview by clicking the Preview button the result will look like Figure 4.
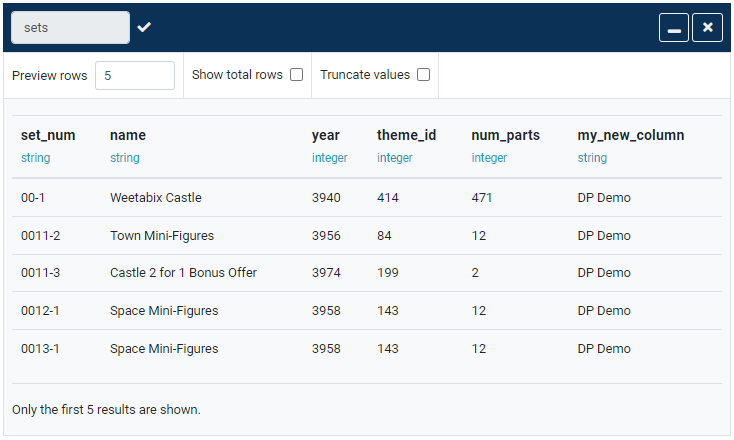
Notice the following:
- the values in the
yearcolumn have been multiplied by two - a new column named
my_new_columnhas been added containing the literal value 'DP Demo'
When mapping a column using an expression, any Spark SQL function can be used. For example, let's use the concat() function to append the the set_num column to the the name column with a space in between. The operation widget will look like Figure 5.
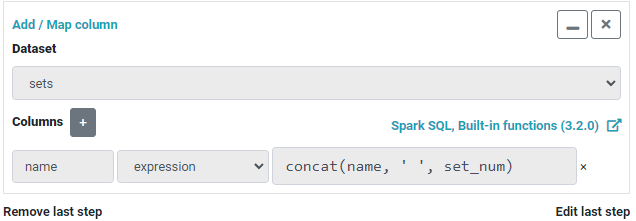
concat() Spark SQL function to map the name columnThe result will look like Figure 6.
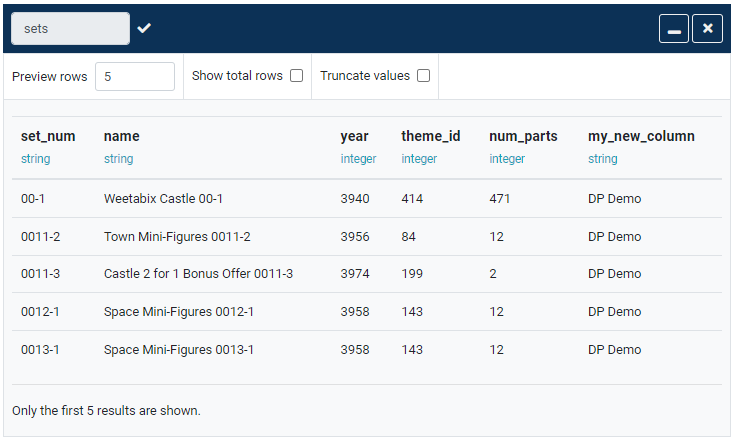
name column with set_num concatenated to itNote how the values in the name column had the values from set_num appended to them with a space in between.
Mapping columns this way is a powerful feature in Data Pipelines. All of Spark's built-in functions are available when using expressions.