How to connect to SQL database from Data Pipelines
Data Pipelines lets users connect to various SQL databases via JDBC
Data Pipelines lets users connect to various SQL databases via JDBC. All SQL connectors are bidirectional meaning they can be read from and written to.
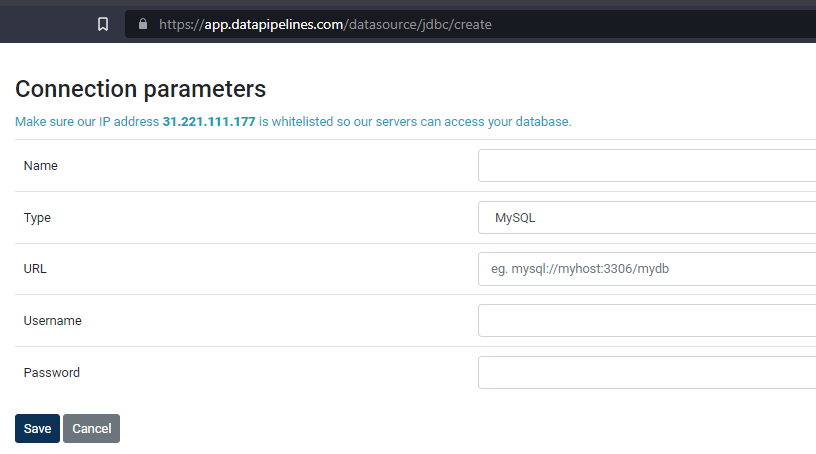
To create a connection, go to Connections -> SQL Database. Make sure Data Pipelines server's IP address is whitelisted in the firewall you may be using and that the connection port is open, otherwise the pipeline will fail to connect. The specific IP address you need to whitelist will be displayed on the Connection Parameters screen (Figure 1).
Currently the following types of databases are supported officially:
- MySQL
- SQL Server
- PostgreSQL
- AWS RDS
- AWS Redshift
- Azure SQL
You can also use these to connectors to connect to the database of any SaaS solution as long as the database is one of the supported types.
The connection URL will look different depending on your database vendor. For example, for MySQL, PostgreSQL and SQL Server the connection string will look similar to these:
mysql://mydbhost:3306/mydatabasepostgresql://mydbhost:5432/mydatabasesqlserver://mydbhost:1433;databaseName=mydatabaseThe connection string may contain additional query parameters, for example time zone. Note that the database name needs to be specified in the URL.
When scheduling a pipeline to write to a JDBC connection, the following configuration options are available:
- Target connection: the JDBC connection you have set up under Connections -> SQL Database
- Table: the table to write to
- Timestamp: if this is enabled then the table name will have a timestamp appended to it. This way you can write data to a new table every time the scheduled pipeline is executed.
- Truncate: if this is enabled, the destination table will be truncated (cleared) instead of dropped. Use this if you want to preserve the table's schema.
- Save mode: this can be one of Overwrite (overwrites the table), Error if Exists (pipeline fails if table exists), Ignore (pipeline completes successfully if table exists but no data will be written) and Append (append new data to table and preserve current data)
To be able to write to an SQL database, make sure you connect with a user that has write privileges - CREATE, INSERT, UPDATE, DELETE, DROP. Which of these privileges the user will need depends on what Save Mode is being used for the write operation. For example, to overwrite an existing table the user you are connecting with will need to have CREATE, INSERT and DROP privileges. To truncate the same table (which preserves the schema) the database user will need DELETE and INSERT.
Checking and granting privileges is slightly different for each type of database. For example in MySQL you can check a users privileges like so:
mysql> SHOW GRANTS FOR 'myuser'@'mydbhost';
+---------------------------------------------------------------------+
| Grants for myuser@mydbhost |
+---------------------------------------------------------------------+
|GRANT SELECT, INSERT, UPDATE, DELETE, CREATE, DROP, RELOAD, SHUTDO...|
+---------------------------------------------------------------------+For support and any questions about your specific use case contact us.