How to push down SQL query to database
Increase your data pipeline's efficiency by using an initial SQL query to load data.
To learn about setting up a connection to an SQL database using JDBC read How to connect to SQL database from Data Pipelines.
When you read data from an SQL database in Data Pipelines, the underlying Apache Spark engine will attempt to load the whole table into memory then apply the transformation steps defined in your pipeline. While this may not be an issue for small tables, it will affect performance for larger ones.
The source database will always be in a separate physical location from the Data Pipelines cluster processing the data, so transferring a whole database table may take a long time, depending on the size of the table.
It is usually a good idea to use an initial SQL query that will be "pushed down" to the source database, reducing the size of the data transferred.
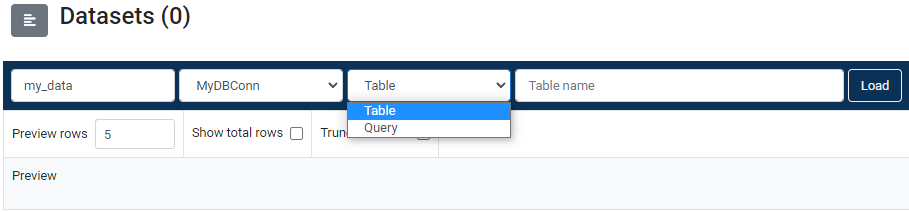
In its default state, the SQL database table loader widget will expect a table name (Figure 1.) so it can load the whole table into memory by transferring all the data from it. By using the Query option, it will delegate the specified query to the source database which will execute this query instead of the Data Pipelines cluster. This technique can significantly reduce the size of the data transferred over the internet.
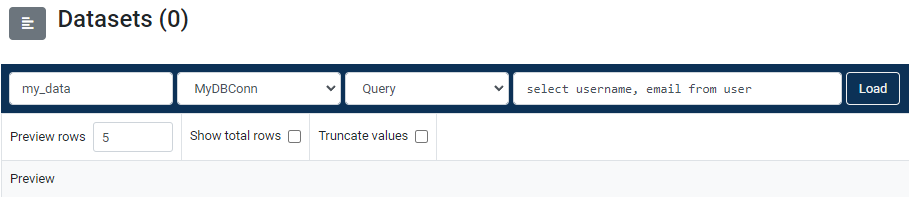
In the example in Figure 2, the query select username, email from user will be executed by the source database. Only the username and email columns will be transferred to Data Pipelines. If the user table had 10 columns then using the above pushdown query would have saved approximately 80% of unnecessarily transferred data.
In summary, asking only for data that will be used in the pipeline can result in significant savings in data transfer costs and time.