Export output from AWS S3
Download your reports delivered to AWS S3 directly via Data Pipelines
File-based formats such as CSV or ORC delivered to AWS S3 can be downloaded directly via the Data Pipelines UI without having to visit the AWS S3 console.
To do this, create a pipeline and either use quick write or schedule a run that delivers the output to AWS S3 (or Hadoop if your solution is self-hosted) in one of the available file formats. Once the pipeline run is successfully completed, you will see an eye icon under Actions in the Recent Runs section.

In Job Output view the Download option will be available.
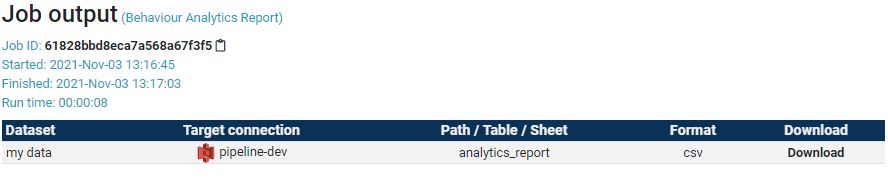
The downloaded Zip archive will include one or more output partition files created by the job.
Note that only file based output can be downloaded this way. The input data (from which the output is created) can be in any format.
It is possible to download data from other types of data stores by first creating a pipeline that writes them to AWS S3.